 30 May 2025
30 May 2025 
Maarten Rits
Product Owner Everyday AI and Automation
Scotty: The First GenAI Chatbot at Elia Group
Scotty was designed to be the all-in-one GenAI chatbot solution at our company. Since Elia Group’s mission does not include building large language models (LLMs) for such use cases, we decided to integrate the models from OpenAI, already available through the Microsoft Azure ecosystem we partially rely on. We built this solution for a seamless integration with multiple internal data sources, enabling Scotty to access the company’s internal knowledge using retrieval-augmented generation (RAG).
Design Choices
To ensure that our chatbot solution could help employees work more efficiently, we prioritised making it easily accessible for every user. Since Microsoft Teams (MS Teams) was already widely used within the company, it was the ideal platform for integration. This allowed employees to interact with the chatbot in a familiar environment, offering a seamless user experience that felt like a natural extension of their existing tools.
We initially decided to build a Microsoft Bot Framework App, as at the time it was the most straightforward way to create an app within MS Teams. However, we are aware that this approach might become deprecated, since Microsoft now recommends using Copilot, which we are currently testing at Elia Group. As illustrated in Figure 1, this setup involved having three key components: the Bot Framework App, a Bot deployment within Azure and the App declaration within MS Teams.
The Bot Framework App communicated with a Generative Pre-trained Transformer (GPT) deployment within Azure. In our solution, GPT generated answers based on user queries, which were then routed back to the user through the bot.

Figure 1: Scotty as Bot Framework App
Communication with the GPT model took place within an agent context, which enabled the model to use specific functions. The first function was to search within files: users could upload a file, and the GPT would read it to extract information or generate a summary. We also implemented a function to access our internal data. When the GPT detected that internal information was needed, it could call this dedicated function. This triggered a request to our RAG infrastructure, which returned the most relevant pieces of internal documents.
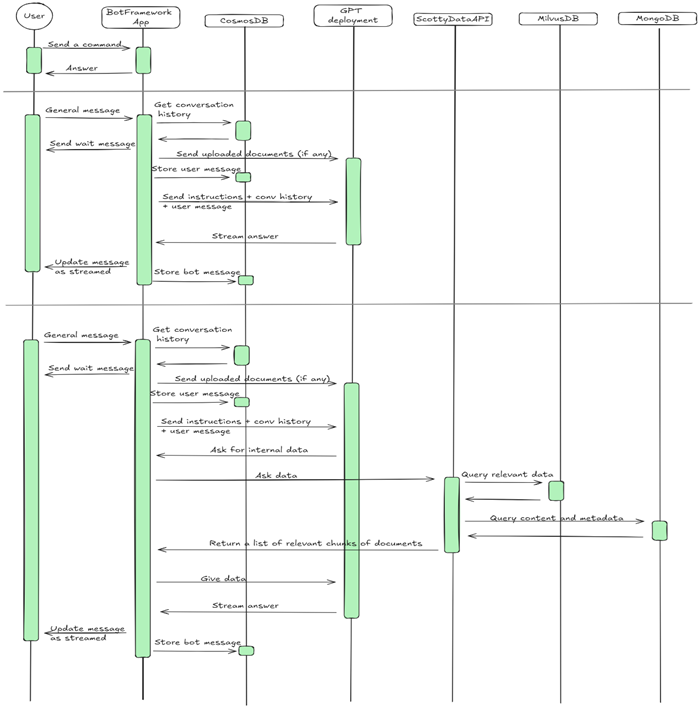
Figure 2: Scotty Message Flow
Authentication was handled through our Entra ID.
More specifically, the system was structured as follows, as also shown in Figure 2:
- ScottyDataAPI: The main component of the RAG architecture. This web Application Programming Interface (API) receives text documents and manages both their storing and retrieval.
- MongoDB: Used to store documents in plain text, allowing access to both raw content and metadata.
- MilvusDB: Used to store documents as vectors, enabling similarity-based search.
- HarvestingAPI: Collects documents from various internal sources (e.g., Intranet, SharePoint, etc.) and sends the formatted documents to ScottyDataAPI. It also stores a SharePoint delta link in MongoDB.
- HarvestingTrigger: An Azure Function that triggers the HarvestingAPI at the scheduled intervals.
At a later stage, we encountered issues with Milvus. The deployment in the Kubernetes cluster was not stable. To ensure a reliable service, we replaced Milvus with Azure AI Search.
Future Outlook
We are aiming to build a new version of the chatbot and expand the functionalities present in the current version. In this section, we outline our key development goals, which include:
- User Control: Provide our users with more granular control over the AI's behaviour, potentially including the ability to select between different models.
- Extensibility: Design our system to easily accommodate new AI models, features, data sources and technologies.
- Interoperability: Facilitate integration with third-party applications and internal services by using standardised protocols such as Model Context Protocol (MCP) and Agent2Agent (A2A).

Figure 3: Further refinement of our GenAI chatbot
The architecture must support the creation of dedicated RAG or GraphRAG systems tailored for different business units and support the access to internal data specific to certain departments, controlled by user permissions. It should provide templates to facilitate the duplication and customisation of knowledge access systems. The system architecture must support the future addition of AI-driven agents. We plan to implement an orchestrator for multiple specialised agents, to handle different tasks. The core orchestrator should be capable of redirecting user requests to the appropriate agent or potentially to specialised sub-orchestrators for complex, multi-step tasks.
As an intermediate step, we are already experimenting with these ideas in a use-case specific to Elia Group. As shown in Figure 3, the following concepts expand on areas that may not have been fully explained in earlier sections:
- Brain: A multi-agent system (using LangGraph) where queries are processed. It interacts with the User Interface (via A2A) and the Knowledge Base (via MCP) to fetch required data and formulate answers.
- Content Extraction: Extracts text and structured content (using Optical Character Recognition) from various document formats with LLMs.
- Query Enhancement: An agent-based service that automatically detects ambiguous or complex queries and interacts with the user (via Brain/UI) to refine them.
- Testing System: An automated evaluation system that uses business-provided dataset to access performance (e.g., retrieval quality, response relevance) upon changes.
As mentioned at the beginning of this section, we also envision the inclusion of multiple models and adapt the interaction between the UI and the Brain to facilitate this. These features are still under development, and their success will depend on further testing and evaluation. We remain committed to advancing this work in a thoughtful and responsible way. We are excited about what lies ahead and look forward to sharing more as the journey continues. Thank you for reading — and stay tuned for future updates!

No results found


